I spoke with Sayan Sanyal who’s a Data Scientist at Twitter on their Notifications team.
He originally studied Computer Science as an undergrad before attending graduate school at Berkeley’s School Information with a focus on Data Science.
A few things that stood out to me were his ability to reason about the benefits of his engineering degree on his day to day work and his thoughts on navigating different types of organizations.
In highschool, I was certain that I wanted to do something quantitative but I wasn’t sure what it would be. I was equally interested in economics, physics, or other engineering pathways. However, given cultural proclivities in India and oppurtunities available, computer science seemed to be the quantitative pathway that was the most easily available to me.
Once I started studying Computer Science, though, it became fairly clear to me relatively quickly that it could be applied to many different things - note that at the time, data science wasn’t really a thing. It was more around the line of analytics and there were certain companies that were trying to do things around that space, so that’s what I decided to explore further.
Right after undergrad, I got into a business intelligence and analytics role. I think those types of roles are super interesting but I essentially just wanted to do more math. It boiled down to being able to understand and apply things in a slightly more sophisticated way, rather than just counting things and being able to display them.
I think that analytics is important however there are certain questions we aren’t able to answer. And for these questions, you need to infer things. We need to go beyond the data that’s available to us and think about processes that haven’t been observed. In order to do that, you need a different set of techniques - whether that be predictive or inferential in nature. And that’s what interested me.
It mainly consisted of 3 parts. One is ETL, which is basically getting data from place A to place B and ensuring that the data is cleansed. I think being able to build robust pipelines is a skill that I’m still leveraging today in the data science world.
The second aspect of it was the data modelling. That is trying to figure out how you would shape data that would enable different kinds of analysis. So for instance, this is where I learnt about snowflake versus star schema, ensuring transaction processing, and other things like that.
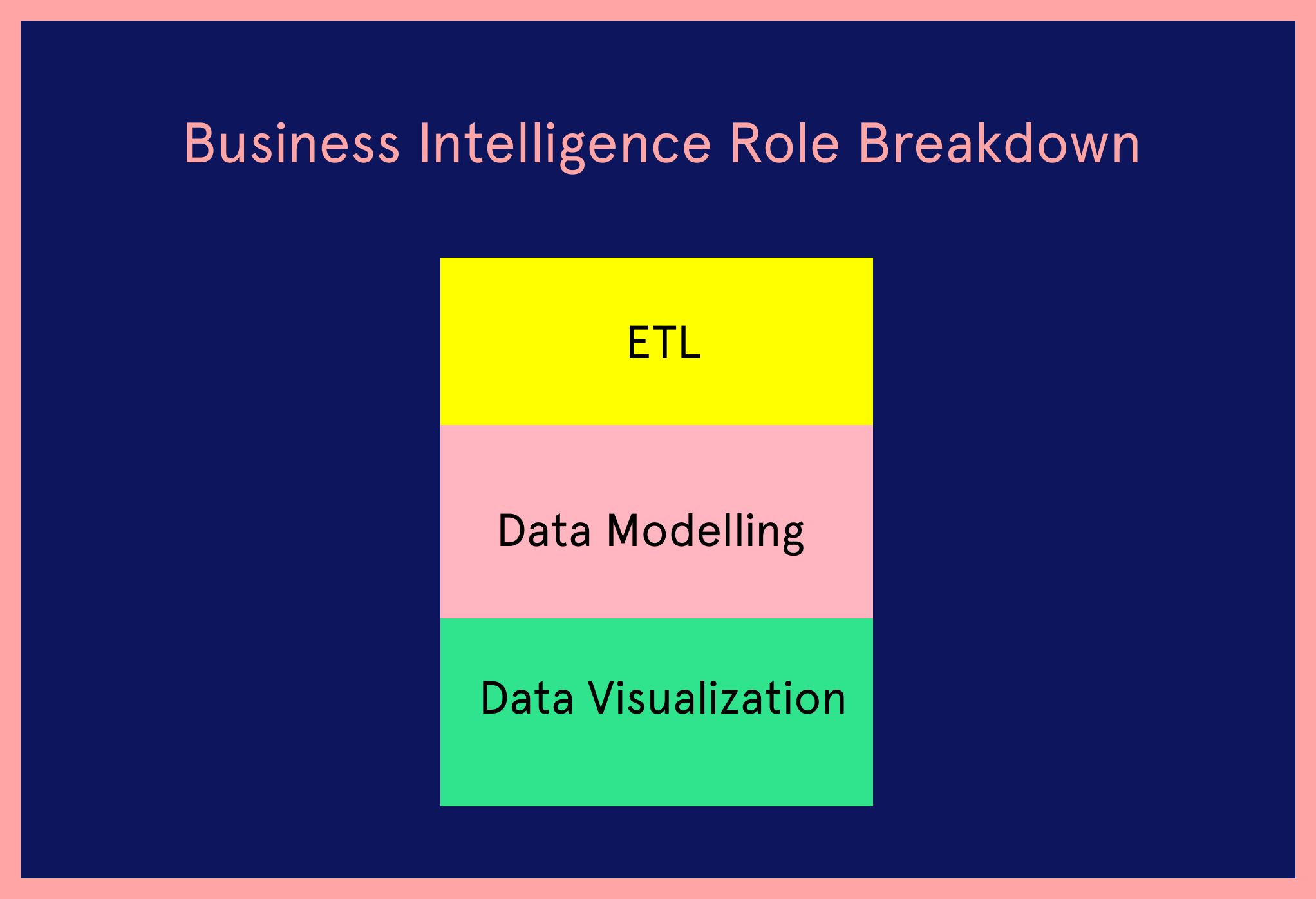
The third aspect of it was data visualization - so the dashboard building part. I think these three skills I just mentioned are useful even when you’re not in the analytics space.
The only thing that was transferable was the idea of normalization and that I had skills in trying to understand how programming works. I knew how to reason through challenging problems, I understood o-notation, I knew the fundamentals of databases, I knew how distributed systems worked - but mainly everything else was picked up on the job.
For instance, how should pipelines be structured in a way that they are fault tolerant? How do we implement error handling? These are things that I picked up on the job.
One of the projects I was working on at the time involved understanding weights and their impact on funding - and I knew that I would be able to do this via regression, but I didn’t feel like I had the mathematical chops to do it in a nuanced way. I thought that understanding data better and the statistical foundations behind this analysis was something I wanted to invest in further, so I decided to go to grad school.
My two years at Berkeley challenged and pushed me to a degree that I hadn’t ever done previously. It took a lot out of me but I’m very glad for it. It made me question knowledge gaps that I had from undergrad and I tried to fill those as rigorously as possible.
The good thing about grad school is that it’s a choose your own adventure type of sport. Unlike undergrad where a lot of the programs are more structured, I would say over here I was able to have much more freedom over what I wanted to focus on. I spent a lot more of my time learning things that interested me. So for example, I went really deep into natural language processing and ended up being a teaching assistant for some of those classes.

I also worked with a professor trying to understand developmental economics using machine learning on satellite data. I spent a lot more time in grad school doing machine learning than causal inference, but now I do a lot more causal inference work than the sort of machine learning that I did in grad school.
Going a bit deeper into economics - it’s probably the only other space doing a lot of observational causal inference right now. And that is a space I’ve been inspired by and spent a lot more time learning about whilst at Twitter.
So for example, I read a lot of papers by researchers like Susan Athey, because they’re able to take techniques in machine learning and able to apply them in the field of causal inference, which is something that marries a lot of the questions that come up very often at Twitter.
I work on the Notifications team. I’ll speak about 3 projects I’ve recently worked on.
One is far more engineering in nature. It involves building up a library using pyspark and python that helps you aggregate experimental data and perform statistical tests on them. This allows you to do flexible experiment analysis on Twitter data.
Another project I was working on was based more on observational causal inference. Trying to estimate the effect of a customer action on their long term user behavior. These are things you can’t always experiment with, so at that point in time you need to use observational techniques to do that.
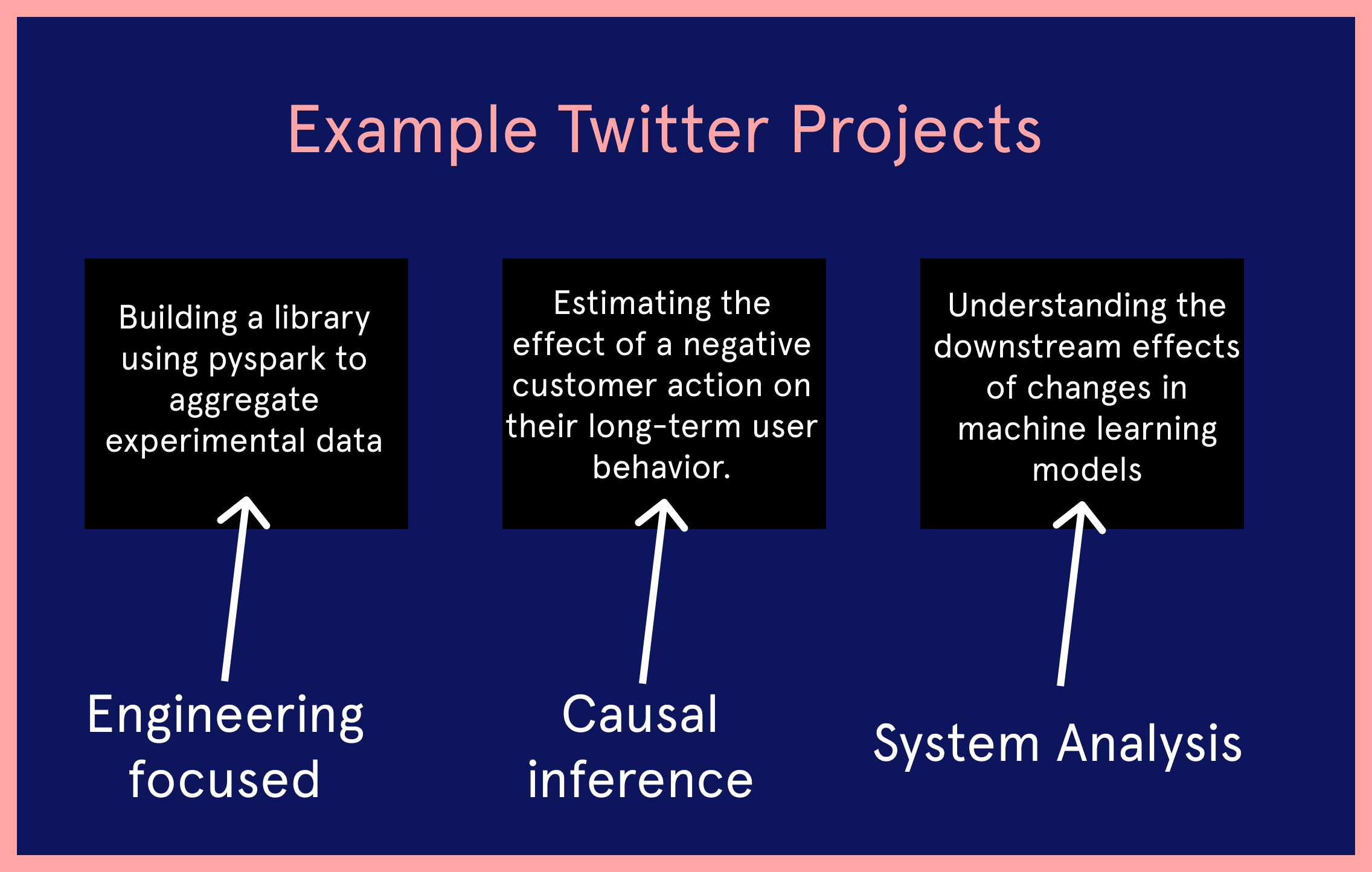
Finally, another project was focused on trying to understand what happens when you change a machine learning model in one space and the downstream effects of that on the recommendations you end up getting in the notifications space. So trying to figure out how different candidate generation processes work and how they affect models is what I worked on.
As you can see, sometimes these projects include analysis of systems, sometimes they include observational studies, and sometimes it’s just plain engineering. Most of the time, I have one main project and other small projects.
All the time! You can’t work without collaborating with them. I most closely partner with my engineering tech leads and my product partners.
I hope you're enjoying the interview. I release interviews like this once a week along with my best content. Sign up below to get it delivered straight to your inbox.
There’s a triumvirate in terms of product, data science, and engineering. So when trying to understand how to make the product better, a lot of the time we also take into account what user research has to say or we’ll also look at a design hypothesis that may have been laid out.
Data Science allows for a wide variety of roles. The way I look at it: I am better placed to do some of the systems work or some of the engineering work compared to some of my peers because of my engineering background, but that doesn’t make me a better data scientist.
They have other skills that they’re able to bring in that I perhaps won’t be able to bring to the table because of my background. So I would say that data science is a very wide space where you’re able to bring in your unique skill sets and shine.
The thing about Twitter is that being as large as it is, it still feels like a terribly small company compared to our other peers. For instance, our ratio of active users to number of people working here - that’s a really big ratio compared to some other companies in consumer tech.
One of the things that has been instructive for me is observing how planning, prioritization and strategy works across a larger company. Especially when there are multiple directions in which a company could be pulled. So being able to understand how to make an impact in that sort of an environment - which can get quite messy - has been a great learning experience.
I think when I was getting into data science I over-index on technical skills. I think most people over-index on these skills and while it is always advantageous to go deep on certain topics, nothing beats being able to balance impact with rigor. One of the differences between academia and industry that I learnt through work is that we need in industry is anything that improves the status quo. It doesn’t need to be necessarily perfect, but it needs to ensure that wherever we are today, it is measurably better than that. And as long as that is true, you don’t need to spend 80% of the time polishing 20% of the last mile.
The second thing I’ve learnt how to do better is communicate succinctly and strategically. Being able to understand and collaborate effectively across different functions. Understand what priorities are and be able to frame things and navigate large organizations - these are all skills that are hard to develop.
You can pick these skills up outside of industry too, though. So say you’re at a large organization at school - people are the same. Across different stages, the way social interactions work out are not very different from one another. As long as you’ve navigated complex social systems before, there are repeatable skills you can pick up that will help you in industry.
Sayan was a pleasure to speak with - feel free to reach out to him on Twitter or Linkedin. If you’d like to read more data science interviews like this, I suggest this one with Divyansh at Uber or this one with Eugene at Amazon.
Some people call it a newsletter - I call it a good time. I write about tech careers and how you can get ahead in yours. It’s my best content (like this case study) delivered to you once a week.